Metabase – Chaîne DataViz dockerisée (PostgreSQL + Dashboard)
Docker: Subventions – Dashboard Metabase
Je voulais une chaîne DataViz locale, reproductible : PostgreSQL pour les données, Metabase pour l’analyse, et Docker Compose pour démarrer/stopper le tout en une commande. L’objectif : packager l’infra, structurer la donnée et exposer des indicateurs métier clairs.
- Catégorie : Application / DataViz
- Contexte : VM Debian 12 (local)
- Livrables : BDD démo, questions Metabase, dashboard, scripts de sauvegarde
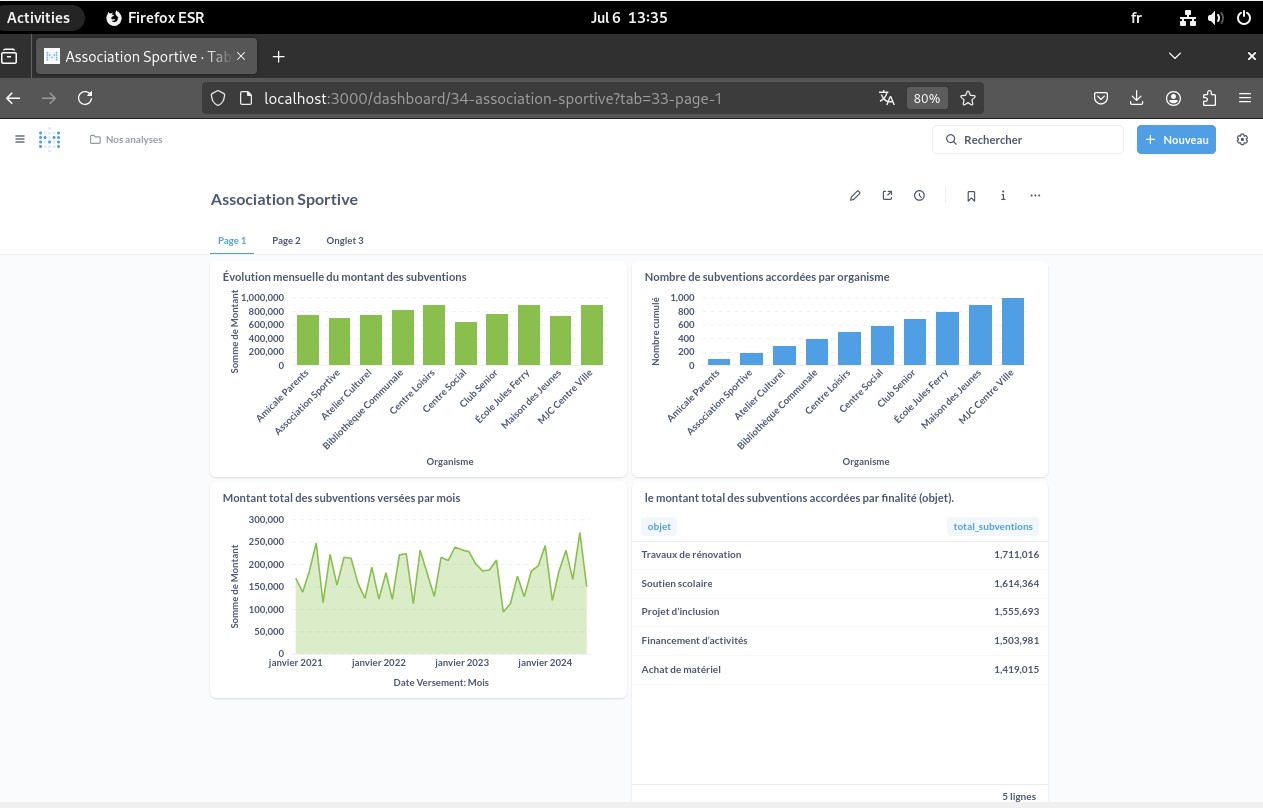
- Côté produit, le besoin est d’analyser des subventions par organisme, finalité et période pour raconter une histoire (évolution, saisonnalité, top bénéficiaires).
- Côté technique, je veux un environnement reproductible : on clône, on lance, et tout fonctionne (base, données, visus). Je privilégie Docker pour la portabilité, et j’ajoute une stratégie de sauvegarde pour la robustesse.
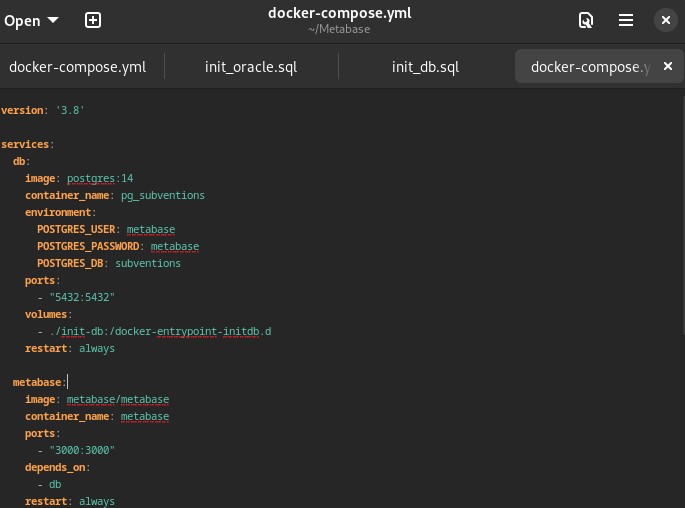
Deux services (db et metabase) sur le même réseau Docker, avec
volumes persistants pour ne pas perdre l’état. Je peux redémarrer la stack
sans reconfigurer Metabase ni la base.
version: "3.8"
services:
db:
image: postgres:15
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: subventions_db
ports: ["5432:5432"]
volumes:
- pgdata:/var/lib/postgresql/data
- ./sql:/docker-entrypoint-initdb.d
restart: unless-stopped
metabase:
image: metabase/metabase:latest
ports: ["3000:3000"]
depends_on: [db]
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: subventions_db
MB_DB_PORT: 5432
MB_DB_HOST: db
MB_DB_USER: postgres
MB_DB_PASS: postgres
volumes:
- metabase-data:/metabase-data
restart: unless-stopped
volumes: { pgdata: {}, metabase-data: {} }
Lancement : docker compose up -d → Metabase sur http://localhost:3000.
Schéma minimaliste : table subventions
(id, organisme, objet, montant, date_versement)
alimentée par un script SQL étendu pour simuler plusieurs années et organismes.
# Injection (depuis l'hôte)
docker compose exec -T db psql -U postgres -d subventions_db \
-f /docker-entrypoint-initdb.d/extended_subventions.sql
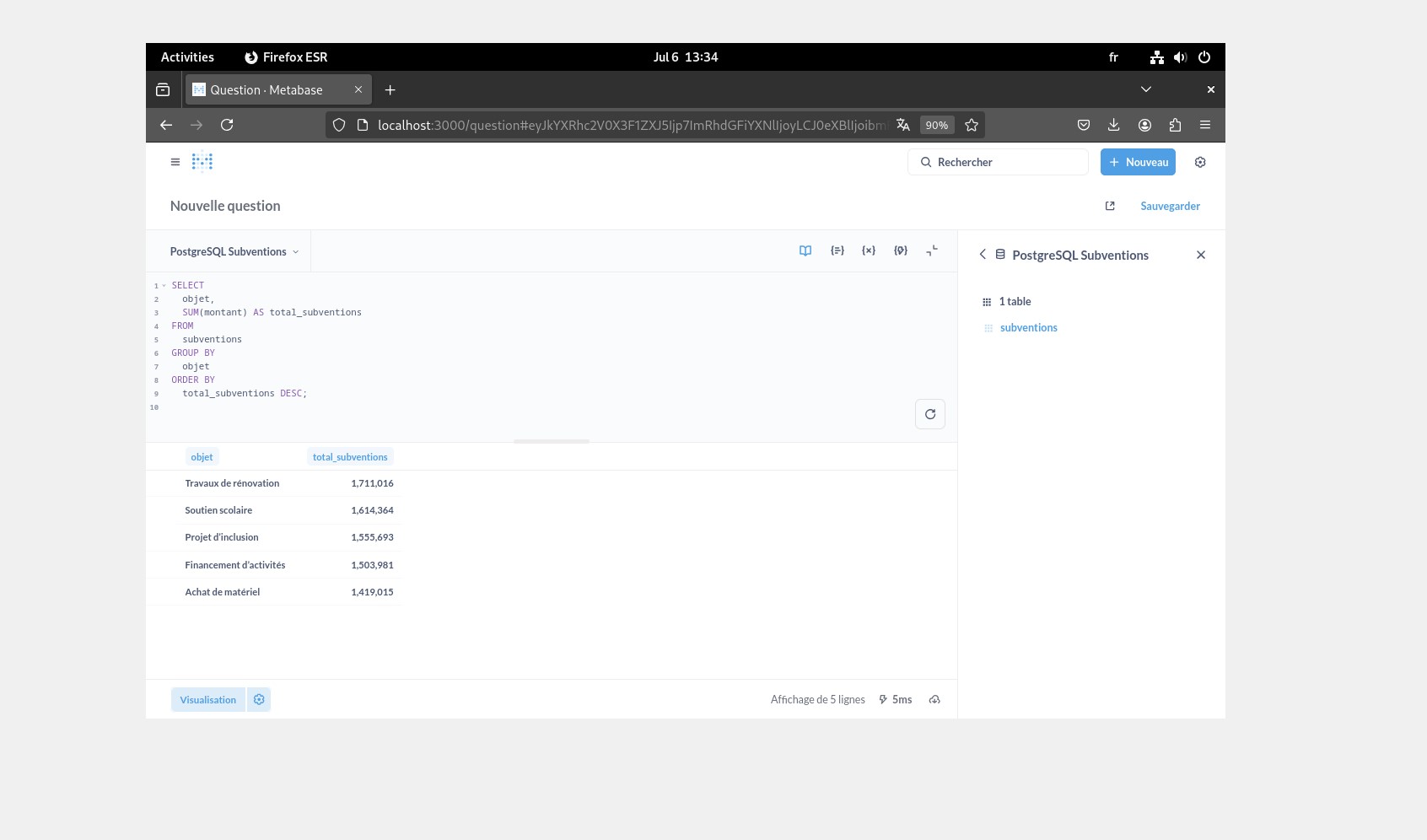
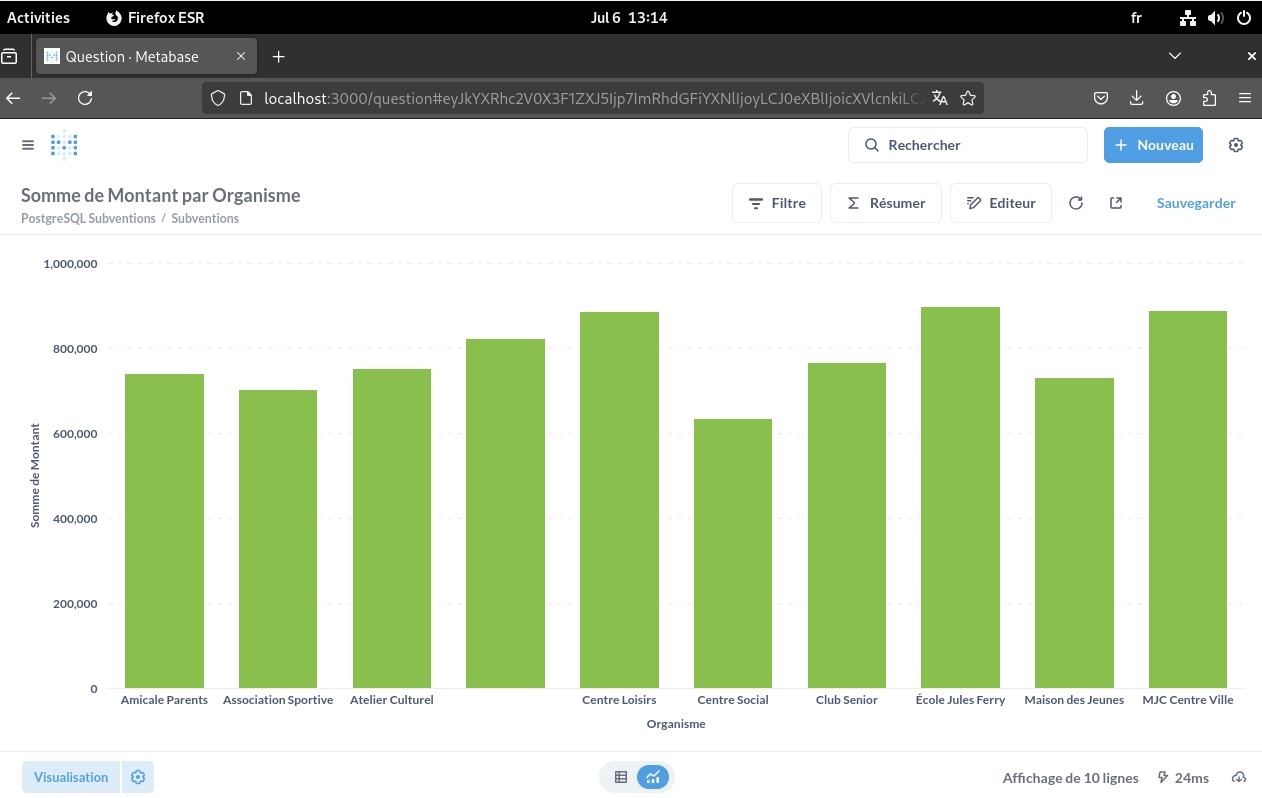
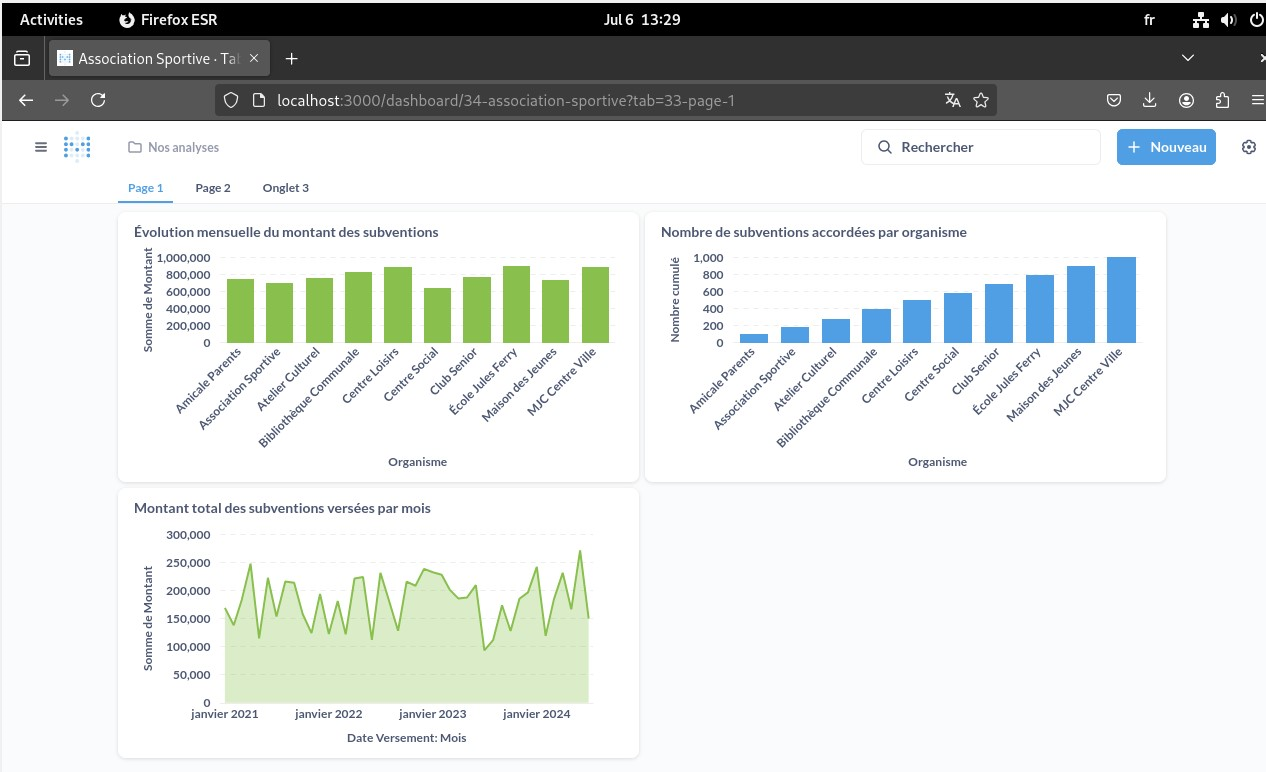
Dans Metabase, je tippe correctement les colonnes (date, nombre), je crée des “Questions” (séries temporelles, top N, répartitions) puis je les assemble en Dashboard (évolution mensuelle, top organismes, total par finalité).
Stratégie adoptée : un script de sauvegarde génère chaque jour un dump horodaté de la base et conserve les 7 derniers fichiers. Cette approche est simple, lisible et suffisante pour une démonstration, tout en permettant une restauration immédiate en cas de besoin.
#!/usr/bin/env bash
set -euo pipefail
STAMP=$(date +%Y%m%d_%H%M)
OUT="backups/subventions_${STAMP}.sql"
mkdir -p backups
# Dump BDD
docker compose exec -T db pg_dump -U postgres subventions_db > "$OUT"
# Rétention 7 jours
find backups -type f -name "subventions_*.sql" -mtime +7 -delete
echo "Backup OK -> $OUT"
# Restauration
docker compose exec -T db psql -U postgres -d subventions_db \
< backups/subventions_YYYYMMDD_HHMM.sql
Cron d’exemple : 15 2 * * * /bin/bash /chemin/backup.sh >> /chemin/backup.log 2>&1
- Variables sensibles dans un
.env(pas d’identifiants en clair dans le YAML). - Volumes
pgdata/metabase-datapour la persistance. - Logs temps réel :
docker compose logs -f db/metabase. - Si exposition externe : reverse proxy et authentification.
- Dashboard métier opérationnel : Evolution mensuelle des subventions, top bénéficiaires par organisme, répartition par finalité/périmètre.
-
Stack reproductible : déploiement «
docker compose up -d», relance sans perte (volumespgdata/metabase-data). - Dataset réaliste : données synthétiques pluriannuelles (saisonnalité, montées en charge), typage soigné (dates, montants) pour des visus fiables.
-
Sauvegarde & restauration : script
pg_dumpavec rétention 7 jours, restauration testée (psql) → rollback rapide en cas d’incident. -
Observabilité minimale : logs temps réel (
docker compose logs -f), variables sensibles externalisées (.env), relance idempotente.
Enseignements clés
- Industrialisation : packaging Docker + init SQL = environnement portable, documenté, prêt pour démonstration/formation.
- Data design pragmatique : schéma minimal mais expressif (temps, finalité, organisme) → indicateurs métier immédiatement actionnables.
- Réflexe DevOps : persistance, secrets, scripts d’exploitation, backups → pensée cycle de vie, pas seulement « déploiement ».
- Traduction valeur : passer de la donnée brute aux insights (tendances, saisonnalité, top N) pour éclairer la décision.