UX Monitoring — Synthetic & Availability (Uptrends)
Surveillance “de bout en bout” — MOA
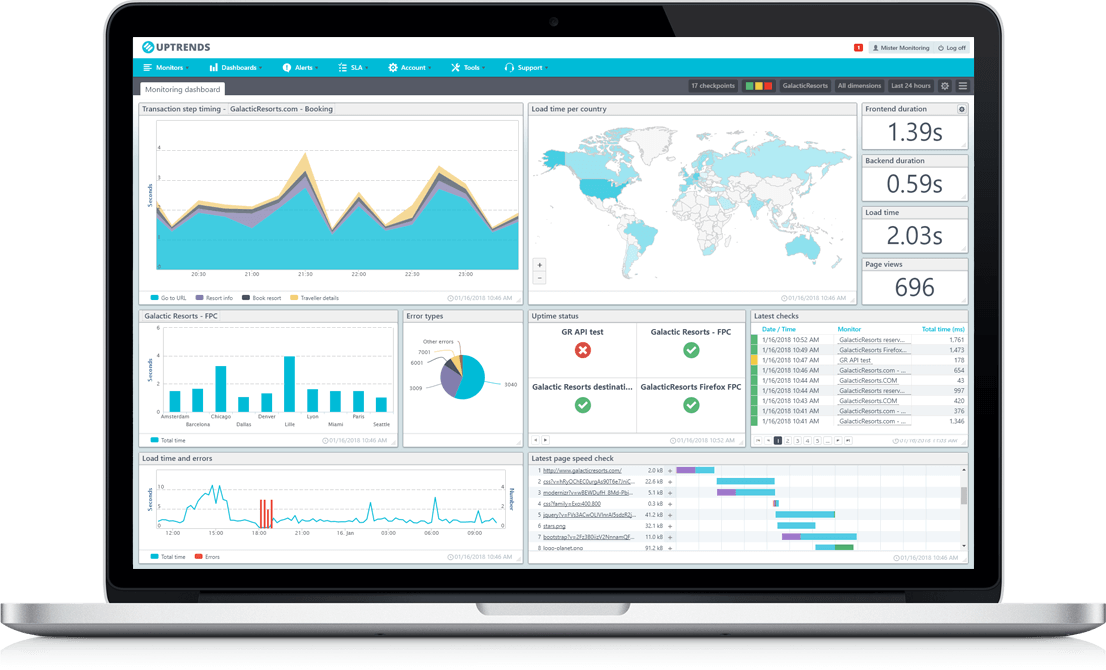
Pour les Ministères sociaux, j’ai piloté la mise en place d’une surveillance synthétique de l’expérience utilisateur avec Uptrends : parcours navigateurs, moniteurs HTTP/API, alerting corrélé et dashboards exécutifs. Objectif : objectiver la qualité perçue (SLA/SLO, p95) et réduire le temps de détection.
- Contexte : Ministères sociaux
- Rôle : Cadrage, sélection, pilotage, recette, gouvernance
- Livrables : Parcours, moniteurs, dashboards, processus d’alerte, PV
- Besoin : mesurer l’expérience utilisateur (disponibilité, temps de réponse, parcours) au-delà des métriques infra.
- Approche : synthetic monitoring “boîte noire” via Uptrends sur plusieurs points de mesure.
- Rôle MOA : cadrage/KPIs, benchmark, sélection prestataire, pilotage, priorisation, validation et recette.
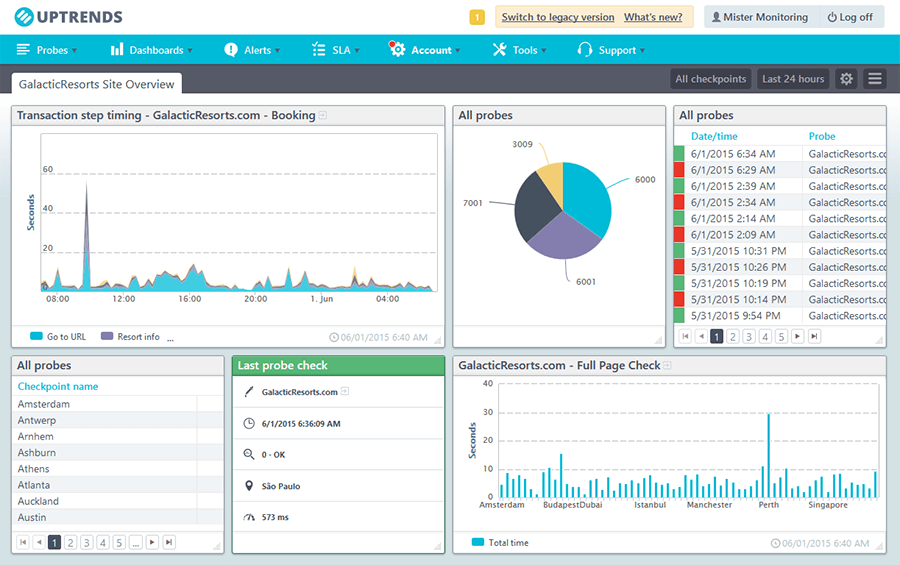
- Périmètre pilote : applis représentatives (auth, front public, API) — moniteurs HTTP/API + parcours navigateurs.
- KPIs : SLA/SLO dispo & p95 des étapes clés, MTTD/MTTA maîtrisés, qualité du signal.
- Réalisation : cadrage → bench → choix → conception parcours → moniteurs → dashboards → processus d’alerte.
- MOE (prestataire) : paramétrage technique, scripting, intégrations d’alertes, dashboards.
- Résultat : visibilité factuelle, alertes actionnables, socle prêt à être industrialisé.
Malgré une infra “verte”, des usagers subissaient ponctuellement des lenteurs/erreurs. L’objectif a été d’objectiver ce que vit réellement l’utilisateur, détecter tôt, et alerter utilement les équipes.
- SLA/SLO dispo ≥ 99,7% (hors maintenance).
- p95 étapes clés ≤ 2–3 s selon contexte.
- MTTD de quelques minutes, peu de faux positifs.
- Tableaux de bord lisibles (équipes & exécutif).
- MOA (moi) : recueil besoins, cadrage, KPIs, choix prestataire, pilotage, validation, recette, conduite du changement.
- Prestataire (Uptrends) : outillage, scripting, moniteurs HTTP/API, intégrations d’alerte, dashboards, support.
- Exploitants/Produit : enrichissement cas, traitement alertes, REX.
3.1 Cadrage (MOA)
- Ateliers besoins : parcours critiques, irritants, maintenance.
- Cahier des charges : types de moniteurs, fréquence, points de mesure, alerting, KPIs et astreintes.
3.2 Étude & sélection (MOA)
Benchmark court (dont Uptrends) : variété moniteurs, stabilité, simplicité, intégrations, coût → sélection actée.
3.3 Conception (MOA + prestataire)
- Parcours navigateur : Auth, Front public, API avec assertions robustes.
- Règles d’alerte : seuils, multi-probe + re-test, escalade (mail/Teams/ITSM).
- Dashboards : par app (technique) + exécutif.
3.4 Mise en œuvre (prestataire, pilotée MOA)
- Moniteurs HTTP/API (codes, SSL, latence, assertions JSON).
- Scripts navigateurs (clics, sélecteurs stables, screenshots à l’échec).
- Intégrations alertes & tableaux de bord.
3.5 Recette (MOA)
- Tests nominaux + pannes simulées (auth KO, 5xx, certifs).
- PV de recette : moniteurs, alertes, dashboards, qualité du signal.
3.6 Conduite du changement
- Guides courts : lire un dashboard, traiter une alerte, enrichir un parcours.
- Revues hebdo : ajustement seuils & stabilisation.
- Réalisé : moniteurs HTTP/API + parcours navigateurs, alerting corrélé, dashboards (app + exécutif), processus d’incident & maintenance, KPIs.
- Options : RUM, APM, tests de charge, onboarding as-code (API), templates par type d’app, industrialisation portefeuille.
- Disponibilité (hors maintenance) par app/période.
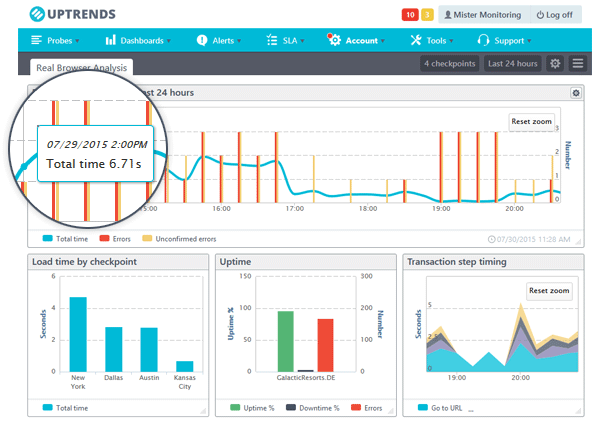
- p95/p99 par étape (auth, page clé, API).
- MTTD/MTTA & qualité d’alerte (faux positifs minimisés).
- Cartes de latence par point de mesure (explication géographique des écarts).
Seuils stabilisés sur 2–3 semaines puis baseline figée par application.
- Comptes techniques à privilèges minimaux, rotation de secrets.
- Whitelisting IP des sondes, restrictions d’accès.
- Pas de données perso dans scripts/rapports, RGPD, nettoyage des captures.
- Cahier des charges & critères de succès.
- Plan de parcours (étapes, assertions) & paramétrage moniteurs.
- Dashboards (app & exécutif) et processus d’alerte.
- Procédure d’exploitation & PV de recette.
- Plan d’industrialisation (templates, priorités).
| Risque | Effet | Parade |
|---|---|---|
| Faux positifs | Alertes inutiles | Multi-probe + re-test, seuils adaptés |
| Parcours qui casse | “Rouge” injustifié | Sélecteurs stables, revue post-release |
| Authent SSO intermittente | Échecs sporadiques | Comptes techniques dédiés, retries |
| Confusion perf “tech”/“perçue” | Mauvaise décision | Dashboards pédagogiques (p95, par étape) |
- “On a mesuré l’expérience de bout en bout, pas juste l’infra.”
- “J’ai cadré les besoins & KPIs, piloté le prestataire, validé moniteurs/alertes/dashboards.”
- “Le pilote prouve la valeur : on voit quand, où et pourquoi ça rame/casse, et qui agit.”
- “Socle prêt à être industrialisé sur d’autres applications.”
- Templates par type d’app (public, SSO, API) & API d’automatisation.
- Nommage/tags standard (service, criticité, équipe).
- Intégration ITSM : auto-ticket, SLA, post-mortem type.
- Communication & formations “flash” pour les équipes.
{
"monitor": {
"type": "http",
"name": "Front public - Page d'accueil",
"frequencySec": 60,
"locations": ["FR-Paris","EU-Frankfurt","EU-Amsterdam"],
"assertions": [
{"type":"statusCode","op":"eq","value":200},
{"type":"content","op":"contains","value":"Accueil"}
],
"alerting": {"retest":2,"threshold":"3/5","channels":["mail","teams"]}
}
}
Illustratif : le prestataire a livré la configuration finale côté Uptrends.